Was macht DeepSeek Chimera so revolutionär? Die AoE-Technologie erklärt
Du möchtest wissen, wie sich die Entwicklung großer Sprachmodelle ohne Millionen-Investitionen realisieren lässt? In diesem Beitrag erfährst du, wie DeepSeek Chimera durch clevere Modellfusion („Assembly of Experts“) eine neue Ära in der KI-Entwicklung einläutet – effizient, skalierbar und fast unglaublich intelligent.
🚀 Das Wichtigste in Kürze
- DeepSeek Chimera ist ein KI-Modell, das durch Fusion bestehender Expertenmodelle (R1, V3) ohne erneutes Training geschaffen wurde.
- Die Assembly of Experts (AoE)-Methode erlaubt es, spezialisierte Fähigkeiten zu kombinieren und gleichzeitig Rechenkosten massiv zu senken.
- Die neueste Version, R1T2 Chimera, ist doppelt so schnell wie R1-0528 und behält trotzdem 90–92 % dessen Intelligenz.
- Perfekt für Aufgaben mit hoher Argumentation – zum Beispiel Logik, Mathematik oder Programmierung.
- Chimera steht unter MIT-Lizenz – Achtung: EU AI Act beachten!
🔍 Was ist DeepSeek Chimera genau?
DeepSeek Chimera repräsentiert einen Paradigmenwechsel in der LLM-Entwicklung. Statt neue Modelle von Grund auf zu trainieren, werden spezialisierte Modelle wie DeepSeek V3 und DeepSeek R1 intelligent zusammengeführt. Klingt einfach? Tatsächlich braucht es hierfür keinen einzigen Token an zusätzlichem Training.

Die Technik dahinter: „Assembly of Experts“ (AoE). Dabei werden nur die gerouteten „Expertentensoren“ – quasi die spezialisierten Denkzellen eines Modells – miteinander kombiniert. Heraus kommt eine Fusion, die schneller, effizienter und fast genauso schlau ist wie ihre Elternmodelle. So etwas gab es bisher noch nie.
Die Eltern: DeepSeek V3 & R1 im Porträt
| Modell | Schwerpunkt | Stärken | Schwächen |
|---|---|---|---|
| DeepSeek V3-0324 | Allround-KI | Schnell, präzise, effizient | Geringere Argumentationsleistung |
| DeepSeek R1 | Reasoning-Modell | Chain-of-Thought, Logik, Mathematik | Langsamer, hoher Ressourcenverbrauch |
| DeepSeek R1-0528 | Upgrade von R1 | Noch besser in Argumentation, weniger Halluzinationen | Sehr rechenintensiv |
Die Fusion dieser Modelle zu DeepSeek Chimera erlaubt es dir, das Beste aus zwei Welten zu nutzen – ohne Kompromisse bei Geschwindigkeit oder Denkfähigkeit.
🧠 Die „Assembly of Experts“-Methode erklärt
Statt mit brachialem Rechenaufwand bestehende LLMs mühsam neu zu trainieren, werden die jeweiligen Stärken – wie bei einem Baukastensystem – modulweise kombiniert. Wichtig hierbei:
- TRIM: Unwichtige Gewichtsunterschiede werden entfernt.
- ELECT: Statistische Mehrheit entscheidet über den Endwert jedes Parameters.
- MERGE: Die Modelle werden durch gewichtete Summation fusioniert.
Das Ergebnis: Extrem präzise Anpassungen, bei gleichbleibender Funktionsfähigkeit. Das ist keine Modellkopplung, das ist gezielte Modellarchitektur-Manipulation.
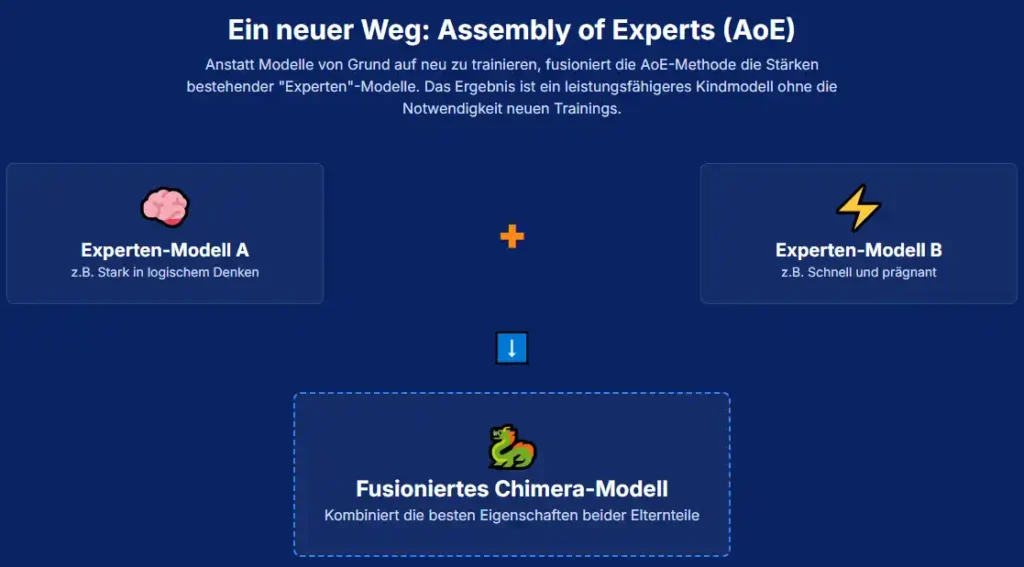
Warum dieses System eine Revolution ist
- Erfordert kein zusätzliches Training
- Enorme Kosteneinsparung gegenüber klassischen LLMs
- Emergente Eigenschaften wie Think-Token-Verhalten entstehen spontan
- Skalierbar & modular – neue Versionen kinderleicht durch neue Elternmodelle
🏁 Performance: Schnell, schlau und sparsam
Die Benchmarks sprechen eine deutliche Sprache: DeepSeek R1T2 Chimera ist ein echtes Arbeitstier. Bei gut 90–92 % der Intelligenz von R1-0528, bringt es:
- ⏱️ 200 % mehr Geschwindigkeit als R1-0528
- 💰 60 % geringeren Tokenausstoß → niedrigere Inferenzkosten
- 🧠 Verlässliche „Chain-of-Thought“-Antworten
- Think-Token Konsistenz erstmals fehlerfrei
Zum Vergleich – hier ein Überblick:
| Modell | Geschwindigkeit | Tokenverbrauch | Denkkraft |
|---|---|---|---|
| R1-0528 | Langsam | Hoch | Sehr hoch |
| V3-0324 | Sehr schnell | Effizient | Begrenzt |
| R1T2 Chimera | Schnell (2x schneller als R1-0528) | -60 % | 90–92 % von R1-0528 |

📌 Wann solltest du DeepSeek Chimera einsetzen?
Wenn dir Effizienz wichtiger ist als absolute Spitzenleistung à la GPT-4 – dann ist die DeepSeek Chimera-Serie deine Lösung. Speziell die R1T2-Version bietet ein perfektes Gleichgewicht zwischen Argumentationstiefe, Tokenökonomie und Geschwindigkeit.
Ideal für Anwendungsbereiche wie:
- Mathematische Problemstellungen
- Logikrätsel, Coding und technische Analysen
- Wirtschaftliche KI-Lösungen mit schneller Ausführung
Empfehlungen je nach Anwendungsfall:
- DeepSeek-V3: Schnelle Textgenerierung, kreative Aufgaben, Assistenten
- DeepSeek-R1: Forschung, komplexe Planung, Agenten-Workflows
- DeepSeek R1T2 Chimera: Preis-Leistungssieger für strukturierte Logik mit geringer Latenz
📎 Der kleine Haken – das solltest du wissen
- Keine Funktionsaufrufe: Aktuell nicht ideal für Tool-Handling/Function Calling
- Regulatorik (EU AI Act): Ab August 2025 gelten neue Regeln – prüfe deine Nutzung im EU-Raum!
- R1-0528 bleibt Benchmark-Spitze: In „hard benchmarks“ noch immer besser – aber langsamer
Aber: Wenn du keine High-End-Forschung betreibst oder nicht mit Tools arbeiten musst, ist R1T2 Chimera oft die bessere Wahl.
📋 Deine Checkliste für den Einsatz von DeepSeek Chimera
- ✅ Du brauchst starke Argumentationsleistung bei effizientem Output?
- ✅ Du arbeitest in strukturierten, logikbasierten Umgebungen?
- ✅ Du suchst eine skalierbare KI-Lösung mit geringem Ressourcenverbrauch?
- ✅ Du willst hohe Denkqualität, aber keine GPT-4-Kosten?
- ✅ Du nutzt (noch) keine Tools oder Funktionsaufrufe?
Wenn du all das mit Ja beantwortest: Dann ist DeepSeek Chimera (speziell R1T2) das perfekte Modell für dich.
📢 Was du aus diesem Artikel mitnehmen solltest
DeepSeek hat mit Chimera einen Meilenstein gesetzt. Statt neue Modelle mit Millionen von Tokens neu zu trainieren, zeigt die Assembly of Experts-Strategie, wie aus Bestehendem Großes entstehen kann – intelligent, schnell und effizient. Die DeepSeek Chimera-Modelle, insbesondere das neueste R1T2, stellen eine attraktive Alternative zur herkömmlichen LLM-Entwicklung dar – und eröffnen einen neuen Weg zu denkenden Maschinen, die nicht nur clever, sondern auch wirtschaftlich sind.
Lass dir dieses Modell nicht entgehen – besonders, wenn du mit begrenztem Budget und hohem Anspruch arbeitest. Die KI-Modellfusion ist nicht nur ein technischer Trend, sondern eine ganz neue Mindset-Ära in der KI-Welt.
Viele Grüße
Dein Radar für die Tech-Welt
Team von TechObserver.de